15. März 2021
Technologiegestützte Untersuchungskonzepte

Von Malik Kheribeche
Eine ausländische Behörde warf einem global tätigen Unternehmen mit Hauptsitz in der Schweiz wettbewerbswidriges Verhalten vor. Dank moderner Computerlinguistik konnte die darauffolgende Faktenermittlung zeit- und kosteneffizient durchgeführt werden.
Das Unternehmen beauftragte uns, seinen externen Rechtsberater bei der Stellungnahme gegen die erhobenen Vorwürfe zu unterstützen. Dabei nutzten wir technologiegestützte Untersuchungsmethoden und fortgeschrittene Analytik, um Schlüsselbeweismaterial aus einer grossen Menge von nutzergenerierten Inhalten zu identifizieren. Kommen Sie mit auf einen Ausflug in die Welt der technologiegestützten Untersuchungen.
Textanalyse durch Computerlinguistik
Moderne Untersuchungen umfassen grosse Volumen von Textdaten, welche kaum in einem angemessenen Zeit- und Kostenrahmen zufriedenstellend analysiert werden können. In diesem Fall wurde dem Kunden eine zweiwöchige Frist für die Analyse von ungefähr 1 Million gesammelter Dokumente, der sogenannten «Dokumentenpopulation» gewährt, um der Behörde eine verbindliche Auskunft zu erteilen. Die Dokumentenpopulation bestand aus Emails, Dokumenten und Excel Tabellen.
Aufgrund dieser knappen Frist war der Einsatz von Computerlinguistik, wie zum Beispiel Text Clustering oder Textklassifizierung, für die Identifizierung von fallrelevanten Informationen ausschlaggebend.
Diese Techniken ermöglichen einerseits eine effektive, explorative Ermittlung des Sachverhalts, falls keine festen Anhaltspunkte bestehen. Andererseits ermöglichen sie aber auch die gezielte Suche nach Informationen, welche zur Bestätigung/Widerlegung einer Vermutung dienen. In beiden Fällen dienen die Techniken dazu, unwesentliche Informationen herauszufiltern und es dem Ermittlungsteam zu ermöglichen, sich auf die informativsten und relevantesten Dokumente zu konzentrieren. Folgend wird nun ein Überblick über die Herangehensweise des Falls und den Einsatz der technischen Methoden gegeben.
eDiscovery Prozess
Das primäre Ziel der Untersuchung war es, die von der ausländischen Behörde erhobenen Vorwürfe zu prüfen.
Verschiedene Hintergrundinformationen, wie zum Beispiel die Erläuterungen der Vorwürfe sowie der daran beteiligten Personen, ermöglichten es, ein Vorgehen zur Analyse der Dokumentenpopulation zu definieren. Die Rechtsberater stellten zunächst eine Auswahl von 20 relevanten Dokumenten, die sogenannte «Vorlage», als Anhaltspunkt für den Verdacht zusammen.
Eine rein manuelle Dokumentenanalyse ohne Eingrenzung der Dokumentenpopulation beansprucht zu viel Zeit. Deshalb implementierten die unternehmensinternen Ermittler zusammen mit den Anwälten einen dreistufigen technologiegestützten Prozess, um dem Kunden eine fristgerechte Stellungnahme bei den Behörden zu ermöglichen:
1. Text Clustering
Das Text Clustering ist die automatisierte Unterteilung der Dokumentenpopulation in Untergruppen, den sogenannten «Clusters». Die Clusters bestehen aus Dokumenten mit Ähnlichkeit in Bedeutung und Kontext. Die Beurteilung der Dokumente erfolgt aufgrund einer automatisierten Frequenzanalyse der Wörter und bedarf damit keiner Beurteilung oder Eingabe seitens der Nutzer. Eine Visualisierung der Cluster ermöglicht dem Ermittler ein schnelleres Verständnis und eine effiziente Durchsicht der Daten.
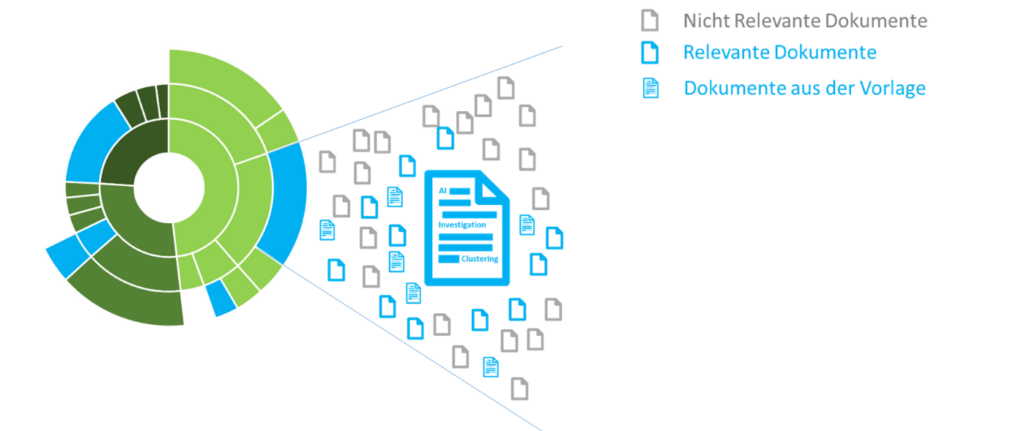
Durch die Durchsicht der Cluster in einem automatisierten Identifikationsprozess wurden die der Vorlage konzeptionell ähnlichen Dokumente identifiziert.
Die Ermittler markierten dann im sogenannten Kodierungsprozess die Dokumente als relevant oder nicht relevant. Diese Kodierung wurde für die Entwicklung eines Textklassifizierungsalgorithmus eingesetzt.
2. Konzepte und Suchbegriffe
Die Verwendung von Suchbegriffen während der Anfangsphase einer Untersuchung ist eine weitverbreitete Praxis, um die Dokumentenmenge für die manuelle Überprüfung durch einen Rechtsberater zu reduzieren. Im Vergleich zu den auf Text Clustering basierten Ansätzen bedürfen Konzepte und Suchbegriffe mehr Inputs seitens der Ermittler. Die Herausforderung bei der Verwendung von Suchbegriffen ist die Definition einer geeigneten Begriffsliste. Diese kommt durch einen oft langwierigen, iterativen Prozess zustande, um zufriedenstellende Ergebnisse zu liefern.
Bei der Analyse der relevanten Dokumente stellten die Ermittler Suchbegriffe fest, die sie zur Identifikation weiterer relevanten Dokumente führten. Durch die Zusammensetzung von mehreren Suchbegriffen entstehen sogenannte Konzeptsuchen. Der Vorteil dieser konzeptbasierten Suche ist, dass sie tendenziell eine bessere Relevanzquote haben, weil sie aus der Terminologie der Dokumentenpopulation stammen und dadurch in ihrem Kontext bewertet werden.
Wenn Suchbegriffe effizient ausgewählt werden, können sie einen hohen Mehrwert schaffen, indem sie mehr relevante Inhalte identifizieren und somit dem Ermittlungsteam wichtige Einblicke in den Fall ermöglichen. Mit dem neu erlangten Wissen kann ein Textklassifizierungsalgorithmus trainiert werden, um die Analyse weiter voranzutreiben.
3. Textklassifizierungsmodell
Beim Textklassifizierungsmodell werden die kodierten Dokumente einem Algorithmus vorgelegt, der versucht, Assoziationen zwischen Dokumenten und den Kodierungen zu ermitteln und diese in der Folge als relevant, respektive nicht relevant einstuft. Diesen Prozess nennt man «Trainingsphase» und er kann, falls weitere Dokumente kodiert werden, wiederholt werden.
Das Ergebnis der Trainingsphase ist das sogenannte «Textklassifizierungsmodell». Dieses lernt während den Trainingsphasen über welche Eigenschaften die relevanten Dokumente verfügen und ist deshalb später in der Lage, neue Dokumente selbständig als solche zu identifizieren. Für neue Dokumente berechnet das Modell eine Relevanzwahrscheinlichkeit zwischen 0 und 100. In der Folge wird das Klassifizierungsmodell auf die gesamte Dokumentenpopulation angewendet. Die Relevanzwahrscheinlichkeit jedes einzelnen Dokumentes wird vom Modell berechnet.
Die Ermittler fokussierten sich auf die vom Modell als relevant eingeschätzten Dokumente. Die verwertbaren Informationen, die für die Behördenanfrage relevant waren, wurden hierdurch maximiert.
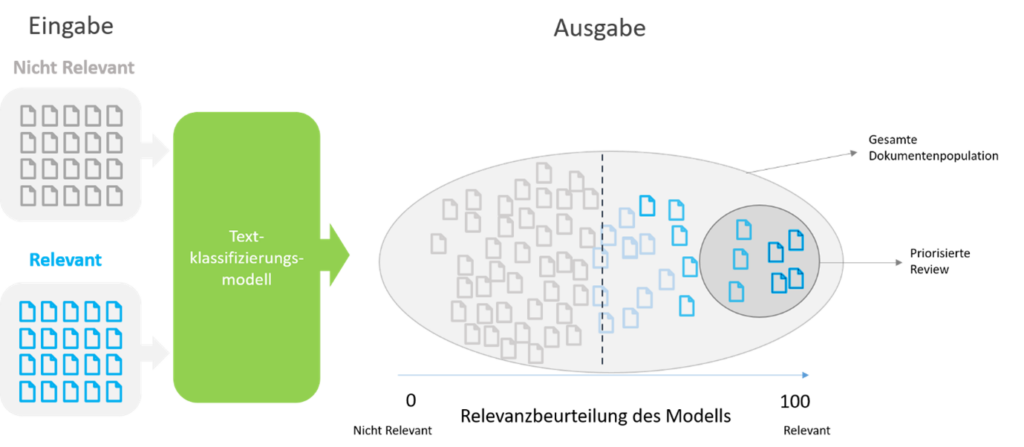
Die Fähigkeit eines Klassifizierungsmodells, die gesamte Dokumentenpopulation zu bewerten, ist in der Praxis äusserst nützlich. Die Leistung des Modells kann durch die kontinuierliche Berücksichtigung von neuen Dokumenten verbessert werden.
Ergebnis der Untersuchung
Trotz anfänglich limitierten Informationen konnten die Ermittler innerhalb von zwei Wochen aus der Dokumentenpopulation von ungefähr 1 Million Dokumenten eine eingegrenzte Analysepopulation von ungefähr 2400 Dokumenten untersuchen. Davon wurden ungefähr 800 als relevant beurteilt, was eine sehr hohe Relevanzquote von 33% darstellt.
Die Kombination von technologiegestützten Methoden ermöglichte den Ermittlern eine beträchtliche Anzahl von Dokumenten zu identifizieren, die für die Untersuchung relevant waren. Basierend auf diesen Dokumenten konnte unser Kunde der ausländischen Behörde eine schlüssige Stellungnahme abgeben.
Zusammengefasst, kann festgehalten werden, dass moderne Ermittler technologiegestützt und multidisziplinär sind. Eine enge Zusammenarbeit zwischen den Rechtsberatern unserer Kunden und unseren eDiscovery Teams bleibt einer der Haupterfolgsfaktoren bei der gerichtsverwertbaren Durchführung von technologiegetriebenen Untersuchungen.
Autor: Malik Kheribeche




Kommentare
0 Kommentare
Danke für Ihren Kommentar, wir prüfen dies gerne.