10. Oktober 2019
Marketing- und Kommunikationsmanagement
Mit Small Data zu intelligenten Business-Entscheidungen – fit für die Connecta
Um intelligente Business-Entscheidungen treffen zu können, benötigt es vor allem relevante Informationen und Wissen. Beides generiert man heute aus Daten.

Mit Small Data haben Sie bereits eine wertvolle Grundlage für das Treffen von Entscheidungen. Doch welche Systeme nutzt der Mensch bei Entscheidungen, weshalb sind Daten besser als Meinungen und wie gross ist der Unterschied zwischen Small und Big Data? Mit diesem Blogartikel erhalten Sie nicht nur Antworten auf diese Fragen, sondern werden vorab auch bestens in mein Thema der Connecta 2019 eingeweiht – gute Lektüre!
Aus der Verhaltensökonomie ist bekannt, dass Menschen beim Treffen von Entscheidungen auf zwei unterschiedliche Systeme zurückgreifen (Kahneman, 2012):
System 1: Man entscheidet schnell, automatisch, intuitiv und emotional. Das fällt uns leicht und geht spontan. System 1 funktioniert gut in vertrauten Situationen und führt zu routiniertem Verhalten.
System 2: Man entscheidet langsam, bewusst, schwerfällig und eher rational. Das ist anstrengend und mühsam. System 2 schaltet sich ein, wenn in neuen Situationen zwischen unterschiedlichen Optionen abgewogen werden muss.
Business-Entscheidungen sind häufig komplex und betreffen neue Situationen. Deshalb erfolgen sie oftmals unter Unsicherheit und aktivieren das System 2. Wie sollen diese bewussten Entscheidungen nun also getroffen werden? Intelligente Business-Entscheidungen weisen zwei zentrale Eigenschaften auf:
- Sie haben ein ausgewogenes Kosten-Nutzen-Verhältnis.
- Sie basieren auf relevanten Fakten bzw. Daten.
Kategorisierung der Entscheidungen nach Wichtigkeit
Business-Entscheidungen haben ein ausgewogenes Kosten-Nutzen-Verhältnis, wenn der Aufwand für den Entscheidungsprozess und die Wichtigkeit der Entscheidung in einem stimmigen Verhältnis sind. Darum gilt es zunächst zu bestimmen, wie wichtig eine Entscheidung eigentlich ist. Jeff Bezos (CEO von Amazon) unterscheidet beispielsweise zwei grundlegende Typen von Entscheidungen (Haden, 2018):
Typ 1-Entscheidungen sind nicht oder kaum rückgängig zu machen. Sie entsprechen einer «one-way door». Ist eine Typ 1-Entscheidung einmal getroffen worden, gibt es kein Zurück mehr. Bezos nennt hierzu den Verkauf des eigenen Unternehmens als Beispiel.
Typ 2-Entscheidungen lassen sich einfach rückgängig machen. Bezos nennt dafür das Angebot von neuen Produkten oder die Einführung eines neuen Preissystems als Beispiel. Solche Typ 2-Entscheidungen mögen sich zwar sehr wichtig anfühlen, liessen sich aber mit vergleichsweise wenig Aufwand wieder rückgängig machen.
Nach Bezos tendieren Unternehmen mit zunehmender Grösse dazu, die meisten Entscheidungen mit einem Entscheidungsprozess für Typ 1-Entscheidungen zu adressieren – selbst solche, die eigentlich Typ 2-Entscheidungen sind. Das mache, so Bezos, Unternehmen unnötig langsam und risikoavers, es hemme Experimentierfreudigkeit und damit schliesslich Innovationen.
Was eine Typ 1- oder Typ 2-Entscheidung konkret ausmacht, mag von Unternehmen zu Unternehmen oder Branche zu Branche unterschiedlich sein. Es ist sicher auch eine Kulturfrage. Doch Bezos‘ Argumentation ist in jedem Fall nachvollziehbar:
- Nicht alle Entscheidungen sind gleich wichtig.
- Der Entscheidungsprozess sollte zum Typ oder der Wichtigkeit der Entscheidung passen.
Daten statt Meinungen als Entscheidungsgrundlage nutzen
Im Entscheidungsprozess sollten relevante Fakten und Daten das ausschlaggebende Element für die zu treffende Entscheidung sein. Relevante Daten schlagen Meinungen als Entscheidungsgrundlage, weil sie der Komplexität und Unsicherheit von Business-Entscheidungen angemessen Rechnung tragen. Doch Daten sind erstmal nur Daten. Darum ist es wichtig zu verstehen, was Daten eigentlich sind, wo Daten herkommen und wie man von Daten zu einer Entscheidung gelangt. Dazu ist das Konzept der DIKW-Pyramide sehr nützlich. DIKW steht dabei für Data, Information, Knowledge und Wisdom (Ackoff, 1989). Der zentrale Gedanke der DIKW-Pyramide ist, dass Daten die Grundlage für Informationen sind, dass Informationen die Grundlage für Wissen sind und dass Wissen die Grundlage für Weisheit ist. Mit jeder Stufe nimmt das Verstehen und damit der generierte Wert zu (Rowley, 2007).
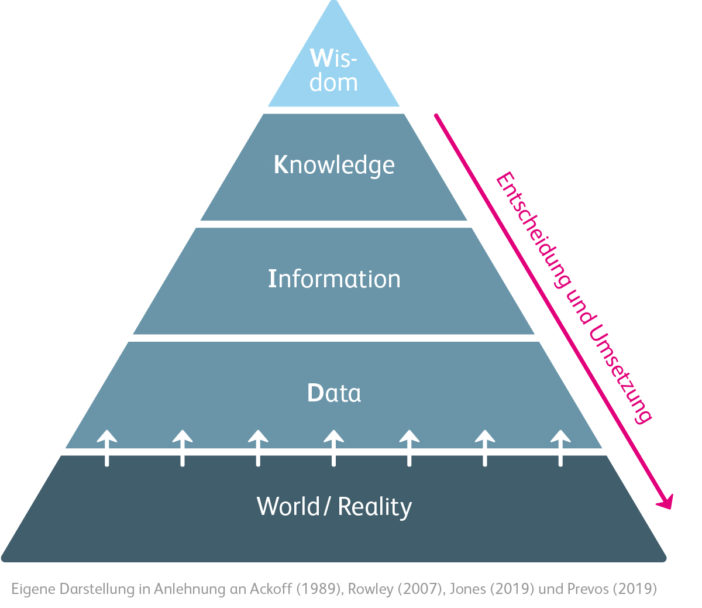
In jüngerer Vergangenheit wurde die Pyramide nach unten hin explizit um die Ebene «World» oder «Reality» erweitert, um unmissverständlich festzumachen, dass Daten Bezug zur Welt haben und nicht im luftleeren Raum schweben. Daten und die Methode ihrer Messung und Erhebung sind dabei untrennbar miteinander verknüpft. Wer Daten verstehen, diese weiterverarbeiten und daraus Schlüsse ziehen will, sollte auch das Zustandekommen der Daten verstehen. Daten sind damit nicht universell objektive Fakten, denn sie wurden mit bestimmten Zielen und Intentionen oder mindestens nach bestimmten Konventionen gemessen oder erhoben (Jones, 2019).
Hinweis Blogpost: Etwas mit Daten oder so – Was machen Data Scientists?
Für intelligente Business-Entscheidungen braucht es nicht nur Daten, sondern deren Weiterverarbeitung hin zu Information und Knowledge im Sinne von «actionable information» oder «Know-how». Mittels dieses Wissens kann eine konkrete Business-Situation verbessert werden (siehe Feedback Loop in der Grafik nach Prevos, 2019).
Daten gestern, heute und morgen – Big Data und Small Data
Bis vor etwa 10 Jahren brauchte man nicht zwischen Small Data und Big Data zu unterscheiden. Quasi alles, was bis zu jener Zeit mit Daten gemacht wurde, entspricht dem, was man heutzutage unter Small Data versteht (Kitchin und Lauriault, 2015). Durch die zunehmende Digitalisierung und Vernetzung werden zumindest Teile der Welt immer mehr «datafiziert», d.h. gemessen, gespeichert und somit in Daten abgebildet.
Hinweis Blogpost: Big & Small Data
Gemäss einer Studie von IDC wird das weltweite Datenvolumen bis zum Jahr 2025 auf ein Niveau von 175 ZB (Zettabyte) ansteigen (Reinsel et al., 2018). Dieser Anstieg ist zurückzuführen auf einerseits mehr Datenquellen und andererseits die zunehmende Häufigkeit oder Frequenz, mit der Maschinen, Maschine-Maschine- oder Mensch-Maschine-Interaktionen Daten generieren. So werden für das Jahr 2025 ca. 4’900 digitale Interaktionen pro Person pro Tag prognostiziert – das ist eine digitale Interaktion alle 18 Sekunden. IDC schätzt, dass bis zum Jahr 2025 ca. 30% des globalen Datenvolumens Realtime-Daten sind, die also in Echtzeit generiert werden.

Die Kriterien Volume, Variety und Velocity werden häufig herangezogen, um Big Data zu beschreiben und definieren. Variety bedeutet die Vielfalt der Daten hinsichtlich Quellen, Format und Struktur. Velocity meint die Geschwindigkeit, mit der Daten generiert werden.
Weitere V-Aspekte, die im Zusammenhang mit Big Data oft behandelt werden, sind Veracity und Value. Mit Veracity ist Datenqualität gemeint. Value stellt eher auf die Fähigkeit von Organisationen ab, aus Daten Wert zu generieren. Daten von möglichst guter Qualität stellen die Grundlage dafür dar, um mittels Daten in Organisationen Wert zu generieren oder Nutzen zu stiften – Garbage in, Garbage out (siehe auch Pyramide oben).
Von Big Data spricht man, wenn Daten in den 3 Kriterien Volume, Variety und Velocity in Kombination jeweils starke Ausprägungen haben, wenn Daten also sehr umfangreich sind (viel Speicher benötigen, Volume), sie viele unterschiedliche Datentypen beinhalten (insbesondere unstrukturierte Daten, Variety) und sie mit hoher Geschwindigkeit oder Frequenz generiert und verarbeitet werden (Velocity). Weitere Kriterien zur Abgrenzung von Big Data sind z.B. Ausschöpfung, Flexibilität oder Skalierbarkeit (Kitchin und Lauriault, 2015). Beispiele für Big Data sind Mobilfunkdaten, Social Media-Nutzungsdaten, wie sie bei den Betreibern der entsprechenden Plattformen anfallen, IoT-Sensordaten oder auch aktuelle Transaktionsdaten grosser Einzelhandelsketten.
Small Data weisen eine begrenzte Kombination der typischen Eigenschaften von Big Data auf. Sie können z.B. gross oder umfangreich wie eine Zensuserhebung sein (Volume), werden aber nicht gleichzeitig laufend aktualisiert und verarbeitet (Velocity). Beispiele für Small Data sind CRM-Daten eines KMU, Website-Traffic und Onlineshop-Nutzungsdaten eines KMU, Daten aus Marktforschungsstudien sowie Daten aus teilnehmenden Beobachtungen und qualitativen Interviews. Im Rahmen von expliziten Studien oder Experimenten werden Small Data oft mit einer konkreten Intention erhoben oder generiert, während Big Data von Maschinen und Sensoren automatisch generiert werden oder ein Nebenprodukt einer digitalen Interaktion/Transaktion sind – oft ohne damit eine konkrete Fragestellung beantworten zu wollen (Kitchin und Lauriault, 2015).
Das erwartet Sie an meinem Connecta-Auftritt
Nebst den bereits eingeführten Themen zeige ich während der Connecta die Möglichkeiten und Grenzen von Small Data auf, verrate Ihnen, was es mit der Weisheit im Hinblick auf Business-Entscheidungen auf sich hat, und gebe Ihnen Tipps für Ihr nächstes Datenprojekt. Und natürlich werde ich Ihnen auch etwas über folgende Grafik erzählen.
Connecta – Wann und wo?
Die Connecta 2019 findet am Dienstag, 22.10.2019 in der Welle7 in Bern statt. Mein Beitrag startet um 14:30 Uhr auf Deck 7 in Raum 7.13. Ich freue mich, Sie in Bern persönlich kennenzulernen.
Quellen
Ackoff, R. L. (1989). From Data to Wisdom. Journal of Applied Systems Analysis, 16, 3–9.
Haden, J. (2018). Amazon Founder Jeff Bezos: This Is How Successful People Make Such Smart Decisions
Jones, M. (2019). What we talk about when we talk about (big) data. Journal of Strategic Information Systems, 28(1), 3–16.
Kahneman, D. (2012). Schnelles Denken, langsames Denken. München: Siedler Verlag.
Kitchin, R., & Lauriault, T. P. (2015). Small data in the era of big data. GeoJournal, 80(4), 463–475.
Prevos, P. (2019). Principles of Strategic Data Science. Birmingham: Packt Publishing.
Reinsel, D., Gantz, J., & Rydning, J. (2018). The digitization of the world: from edge to core. IDC White Paper #US44413318.
Rowley, J. (2007). The wisdom hierarchy: Representations of the DIKW hierarchy. Journal of Information Science, 33(2), 163–180.
Autor: Thomas Wozniak




Kommentare
0 Kommentare
Danke für Ihren Kommentar, wir prüfen dies gerne.