Können Lakehouses einen Paradigmenwechsel anstossen?
Ein Data Lakehouse verbindet die Vorteile eines Data Warehouses und eines Data Lakes. Es wird wohlmöglich alte, starre Strukturen verdrängen.

By Stefan Koch aus dem CAS Business Intelligence & Analytics
Data Lakehouses vereinfachen Dateninfrastrukturen auf radikale Weise. Sie kombinieren die Zuverlässigkeit von Data Warehouses und die Grösse von Data Lakes. Das versprach die kalifornische Software-Firma Databricks vor Kurzem in einem Blogbeitrag über Lakehouses. Darin bezeichnete sie die Einführung der neuen Lakehouse-Technologie als «neues Paradigma im Datenmanagement». Ob das Data Lakehouse eine disruptive Technologie darstellt und das Data Warehouse verdrängt, wage ich (heute noch) zu bezweifeln. Das klassische Data Warehouse hat noch immer seine Daseinsberechtigung. Aber als Apple-Mitbegründer Steve Jobs das erste iPad vorstellte, wurde er zunächst auch als Träumer belächelt. Mittlerweile benutzt die ganze Welt Tablets. Die Frage, ob das Lakehouse einen ähnlichen Siegeszug hinlegen wird, wird sich erst in einigen Jahren beantworten lassen.
Der Bedarf nach einem flexiblen Hochleistungssystem steigt
Es gilt indes schon heute, sich die neue Technologie näher anzuschauen. Denn das klassische Data Warehouse stösst zunehmend an seine Grenzen. Es ermöglicht zwar schnelle Abfragen auf grossen Datenmengen und eignet sich hervorragend für strukturierte Daten. Heutzutage kommen neue Datenquellen aber zunehmend in ganz unterschiedlichen Formaten daher: mal strukturiert, mal unstrukturiert oder semistrukturiert. Die Datenmengen steigen exponentiell an; die Geschwindigkeit, mit der Daten geliefert werden, erhöht sich. Die Anforderungen an die Analyse ändern sich in immer kürzeren Zyklen.
Daher braucht es zunehmend flexible Frameworks, die sich sehr schnell diesen neuen Anforderungen anpassen können. So ist es fraglich, ob das klassische Data Warehouse mit seinen aufwändigen, langen Entwicklungsprozessen noch lange mithalten kann. Für gewisse Daten und Anwendungsfälle müssen also andere Lösungen gefunden werden.
Via Datensee zum Datenhaus
Gewisse Unternehmen begannen darum schon vor rund einem Jahrzehnt, Daten aus verschiedenen Quellsystemen im Rohdatenformat in sogenannten «Data Lakes» abzuspeichern. Ein Data Lake ist ein skalierbarer Datenspeicher, der für grosse Datenmengen ausgelegt ist.
Ein Data Lake bietet unter anderem folgende Vorteile:
- Er kann sowohl strukturierte wie auch unstrukturierte Daten enthalten.
- Er lässt sich für Big-Data-Analysen einsetzen.
- Geringe Kosten.
- Flexible Speicher.
Hybrides Konzept: Eine neue Mischform entsteht
Um die Vorteile von Warehouse und Data Lake zu vereinen, entwickelten viele Unternehmen eine Mischform der BI-Umgebung. Sie speichern unterschiedlichste Rohdaten in grossen Mengen in Data Lakes, während sie Teile davon bei Bedarf in das Data Warehouse laden.
In der Folge davon kommt nun das Lakehouse ins Spiel: Es soll die Vorteile von Data Lakes und Data Warehouses zu einem hybriden Konzept vereinen. Die beiden Systeme werden nicht nebeneinander, sondern als ein neuartiges einzelnes System betrieben.
So entsteht ein neues Systemdesign. Die Implementierung der Datenstrukturen und der Datenverwaltungsfunktionen werden vom Data Warehouse übernommen, die Speicherung erfolgt aber auf dem kostengünstigen und flexibleren Speicher des Data Lakes. Ausserdem kann im Data Lake im Gegensatz zum Data Warehouse direkt auf den Quelldaten gearbeitet werden. Dadurch fallen die gängigen Marts weg.
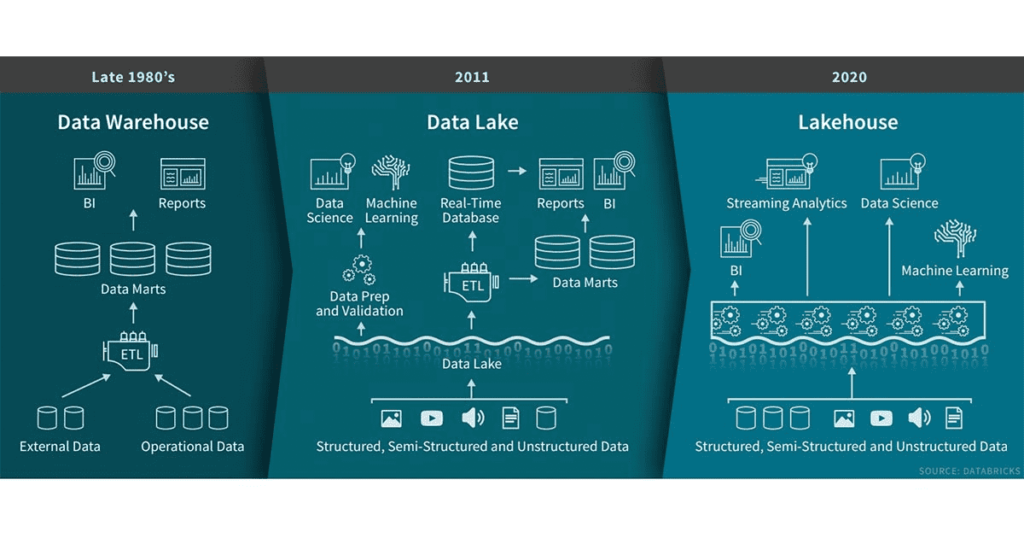
Einige Punkte, die Databricks als Vorteile eines Lakehouses auflistet:
- Entkopplung der Datenspeicherung von der Datenverarbeitung, um eine bessere Skalierbarkeit zu erzielen.
- Offene standardisierte Speicherformate und Schnittstellen.
- Unterstützung für verschiedene Datentypen, von unstrukturierten bis hin zu strukturierten Daten.
- Unterstützung für verschiedene Workloads wie etwa Data Science, Machine Learning, SQL und Analytics.
- End-to-End-Streaming: Durch die Unterstützung von Streaming entfällt die Notwendigkeit separater Systeme für die Bedienung von Echtzeit-Datenanwendungen.
- Kürzere Time-to-Value gegenüber einem Data Warehouse.
Es braucht das richtige Timing und eine gewisse Risikobereitschaft
Daher kann es sich lohnen, beim Neubau einer BI-Lösung dieses neue Architektur-Paradigma in Betracht zu ziehen. Auch bei einer Modernisierung liesse sich ein veraltetes System Schritt für Schritt durch ein Lakehouse ablösen.
Allerdings sollte der Zeitpunkt, an welchem man auf den Zug aufspringt, wohlbedacht sein. Sind wir schon bereit für das neue Paradigma? Ist das Lakehouse schon reif genug? Auch braucht es eine gewisse Risikobereitschaft, um gleich am Anfang einer neuartigen Technologie auf diese Karte zu setzen.
Es ist gut möglich, dass sich zunächst eine Mischform zwischen Data Warehouse und Data Lakehouse durchsetzen wird. Diesen Weg hat Microsoft mit seiner neuen Analyseplattform «Azure Synapse Analytics» eingeschlagen. Dabei setzt das Technologie-Unternehmen bereits mehrere Ansätze des Lakehouses ein, so etwa die Möglichkeit, Daten aus einem Data Lake als virtuelle Tabelle einzubinden.
Es bleibt spannend zu beobachten, wohin die Entwicklung gehen wird.
Veröffentlicht am: 24. Juni 2020

Kundschafter neuer Technologien: Stefan Koch bloggt für unseren Weiterbildungs-Blog aus dem Unterricht des CAS Business Intelligence & Analytics und beschäftigt sich gerne mit neuen Technologien. Er ist Consultant im Bereich Business Intelligence bei der Trivadis AG. Nebst seinen Aus- und Weiterbildungen in der Systemtechnik hat er eine fundierte Ausbildung in IT-Forensik und Cyberinvestigation.
Weiterkommen mit dem CAS Business Intelligence & Analytics: In diesem Weiterbildungsprogramm lernen die Teilnehmenden, wie sie kompetent und systematisch mit geschäftsrelevanten Informationen umgehen. Das CAS vermittelt alle wichtigen Grundlagen, Methoden und Werkzeuge im Bereich Business Intelligence.
Gefällt Ihnen unser Informatik-Blog? Hier erhalten Sie Tipps und lesen über Trends aus der Welt der Informatik. Wir bieten Einsichten in unser Departement und Porträts von IT-Vordenkerinnen, Visionären und spannenden Menschen: Abonnieren Sie jetzt unseren Blog!
Stöbern Sie in unserem Weiterbildungs-Blog: Was lernen unsere CAS-Teilnehmenden? Was sind ihre Fachgebiete? Im Weiterbildungs-Blog der Hochschule Luzern – Informatik erfahren Sie mehr. Aktuelle CAS-Teilnehmende bloggen aus ihren Weiterbildungsprogrammen heraus. Wir unterstützen und fördern die Bloggenden aktiv in diesem Qualifikationsschritt.m:



Kommentare
3 Kommentare
Hans-Joachim Tenholt
Um den Wert dieser Artikel und Aussagen einschätzen zu können, fehlt mir leider ein Datum zur Aktualität. Wann sind die Artikel geschrieben worden ?
Gabriela Bonin
Guten Tag Herr Tenholt, danke für Ihr Interesse. Der Beitrag wurde im Juni 2020 veröffentlicht. Beste Grüsse.
Simon Späti
Sehr schön, vielen Dank. Ich habe mich kürzlich auch intensiv damit beschäftigt, auch damit, wie man so ein Wandeln von Business Intelligence zu mehr Data Engineering Architektur erreichen kann. In meinem Artikel beleuchte ich heutige Probleme und 12 Ansätze, wie man diese mit populären Technologien umsetzen könnte. Bei Interesse wäre hier der Link: https://www.sspaeti.com/blog/business-intelligence-meets-data-engineering/
Danke für Ihren Kommentar, wir prüfen dies gerne.