Die Datenbank der komplexen Beziehungen
Fast 300 Jahre lang war die Graphentheorie kaum mehr als eine Übung. Heutzutage ist sie unverzichtbar, da sie mit grossen Datenmengen umgehen kann und vor allem mit den Verbindungen zwischen Daten.

Die Grundlagen der Graphendatenbanken sind auf die Graphentheorie zurückzuführen. Die Graphentheorie ist ein Teilgebiet der Mathematik, das die Eigenschaften von Graphen und ihre Beziehungen zueinander untersucht. Die Untersuchung von Graphen ist auch Inhalt der Netzwerktheorie, welche sich auf theoretischer Ebene damit auseinandersetzt, wie Netzwerke gesellschaftlich funktionieren. Graphen und Netzwerke sind allgegenwärtig, darum lassen sich zahlreiche Alltagsprobleme mit Hilfe von Graphen modellieren. Leonhard Euler versuchte mit Hilfe von Graphen das Königsberger Brückenproblem zu lösen.
Die Anfänge der Graphentheorie oder das Königsberger Brückenproblem
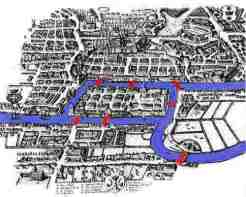
Das Königsberger Brückenproblem beschreibt die Fragestellung, ob es einen Weg gibt, bei dem alle sieben Brücken genau einmal überquert werden können und man zum Schluss wieder beim Ausgangspunkt ankommt. Leonhard Euler bewies 1736, dass ein solcher Weg in Königsberg nicht möglich war, da zu allen vier Ufergebieten bzw. Inseln eine ungerade Zahl von Brücken führte. Der nach ihm benannte Eulerkreis beschreibt genau diese Problematik. Der Eulerkreis zeigt den Weg bzw. die Reihenfolge vom ersten bis zum letzten Knoten (Ufer) und zurück zum ersten, indem jede Kante (Brücke) nur einmal verwendet werden darf. Heute werden diese Methoden der Graphentheorie zugeordnet.
Wie Graphendatenbanken soziale Netzwerke abbilden
In den vergangenen Jahren wurde die Graphentheorie genutzt um Graphdatenbanken zu schaffen, eine Art von Datenbank, bei der die Verbindungen zwischen den Daten ebenso wichtig sind wie die Daten selbst. In sozialen Medien wie Facebook, Twitter oder LinkedIn werden Graphendatenbanken etwa dazu genutzt, um Beziehungen in Form von strukturierten Daten abzulegen. Hierbei wird nicht nur die einfache Beziehung zwischen zwei Menschen aufgezeigt. Die sogenannten Knoten (oder Ecken) können jegliche Formen von Informationen annehmen, zum Beispiel Personen, Facebook-Posts, Twitter-Tweets, Zeitungsartikel, Musikbands, Sportarten usw.
Verbunden werden die Knoten über Beziehungen – im Fachjargon Kanten genannt. Diese Beziehungen beinhalten selbst weitere Informationen, über die Art der Beziehung und wie die beiden verbundenen Knoten zueinanderstehen. Bei Personen kann die Kante Aufschluss darüber geben, wie lange sie sich kennen, wie sie sich kennengelernt haben oder welche Art der Beziehung sie verbindet. Nicht nur die sozialen Medien machen sich die Technologie der Graphendatenbanken zu Nutze. Dating-Plattformen wie Parship machen dies schon längere Zeit, um Personen mit gleichen Interessen und Vorlieben im realen Leben einander näherzubringen.
Beziehungsbasierte Recherchen werden schnell durchgeführt
Wo würden wir heute ohne die Suchmaschinen stehen, welche die alltäglichen Fragen pfeilschnell beantworten können? Die Rede ist nicht nur von Google sondern von allen Suchalgorithmen, welche uns täglich behilflich sind. Behilflich nicht nur dadurch, dass sie möglichst die besten Suchresultate aufgrund der eingegebenen Schlagworte liefern, sondern auch das am besten auf mich abgestimmte Resultat.
Firmen wie Facebook, Spotify, Netflix oder LinkedIn verwenden ihre Informationen, ihr Verhalten, ihre Beziehungen und wie sich Ihre Freunde verhalten, um Ihnen das auf Ihre Person passendste Suchresultat zu liefern. Das alles sind Knoten in einem riesigen Beziehungsnetz von Informationen, welche ein genaues und schnelles Suchresultat nicht selten gestützt auf eine Graphendatenbanken, liefert.
Ineffizient in der Verarbeitung grosser Datenmengen
Die Graphendatenbanken sind spezialisiert auf die schnelle Suche zu einem einzelnen Datensatz, wie zum Beispiel einer Person oder einem Produkt. Wird die Abfrage jedoch analytischer und mehrschichtiger, sinkt die Effizienz der Antwort im Vergleich zu einer relationalen Datenbank. Die Praxis zeigt, dass wenn eine Graphendatenbank mit weiteren Datenbanktechnologien kombiniert werden, ihre Defizite im Bereich Datenverarbeitung und analytischen Abfragen kompensiert werden können. Für das Königsberger Brückenproblem benötigt die Graphendatenbank jedoch keine Unterstützung anderer Technologien, da ist sie mit ihren Ecken und Kanten voll im Element.
Marco Boll ist Verantwortlicher Datawarehouse bei der Zuger Kantonalbank und bloggt aus dem Unterricht des CAS Big Data and Applied Data Scinece.
Mit dem CAS Big Data and Applied Data Science die Digitalisierung mitgestalten
Im CAS Big Data Analytics werden die wesentlichen Aspekte von Big Data und Analytics praxisbezogen vermittelt und aus Managementsicht vertieft.
Über den Informatik-Blog
Hier erhalten Sie Tipps und Neuigkeiten aus der Welt der IT. Wir porträtieren Menschen und schreiben über Technologien, welche die Hochschule Luzern – Informatik mitprägen. Abonnieren Sie jetzt unseren Blog und bleiben Sie informiert.



Kommentare
0 Kommentare
Danke für Ihren Kommentar, wir prüfen dies gerne.