Wie gut sind ChatGPT, Bard und Bing? Ein neues Forschungsprojekt gibt Antworten
Die drei bekanntesten Sprachmodelle im Vergleich: Was können ChatGPT, Google Bard und Bing Chat? Was nicht? Das erforschten unsere Dozentin Marisa Tschopp und drei KI-Studierende der Hochschule Luzern – Informatik. Ziel ihrer Arbeit: Besser verstehen, wie man diese Systeme optimal nutzt.

Von Gabriela Bonin
Wie gut arbeiten ChatGPT, Google Bard und Bing Chat? Was können diese drei grössten, derzeit bekanntesten Machine-Learning-Modelle (LLMs)? LLMs generieren Texte in natürlicher Sprache. In rasantem Tempo revolutionieren sie derzeit die Künstliche Intelligenz (KI). Sie verändern die Arbeitswelt, das Bildungswesen, die ganze Gesellschaft.
Das Video bietet einen Einstieg in die KI-Technologie Machine Learning.
Viele Nutzende wollen daher wissen, welches Modell die beste Leistung erbringt. Genau das untersuchten drei Studierende unseres Bachelor-Studiengangs Artificial Intelligence & Machine Learning. Luca Gafner, Yelin Zhang und Teresa Windlin wurden dabei begleitet von unserer Dozentin Marisa Tschopp. Sie ist Forschungsmitarbeiterin bei der SCIP AG, einem Zürcher Unternehmen, das auf Informationssicherheit spezialisiert ist, und doziert im Bachelor-Studiengang. Die drei Studierenden erarbeiteten ihre Studie im Rahmen eines freiwilligen Praktikums bei der SCIP AG.
Der Spoiler vorab: ChatGPT liegt im Vergleich zuvorderst
Für ihren Vergleich der drei grossen Sprachverarbeitungsmodelle wählten sie einen Verhaltensansatz. Das heisst: Sie konzentrierten sich auf die Antworten der LLMs.
Das Model ChatGPT 3.5 von Open AI hatte in diesem Vergleich das meiste Wissen und gab die genauesten Antworten. An zweiter Stelle stand Bing Chat von Microsoft. An dritter Stelle folgte Bard, das Modell von Google/LaMDA.
Aber Achtung: ChatGPT lieferte häufig auch komplett falsche Informationen. Dennoch schnitt es im Vergleich mit seiner Konkurrenz als das nützlichste Modell ab.
Momentaufnahme in einem rasanten Entwicklungsprozess
Dabei ist zu beachten, dass sich die LLMs derzeit in rasantem Tempo entwickeln. Beinahe im Wochentakt warten sie mit Innovationen auf. Der LLMs-Vergleich dieser Studie ist daher als Momentaufnahme zu betrachten.
Tschopp, Zhang, Windlin und Gafner testeten die drei Sprachmodelle im Zeitraum von März bis April 2023. Sie veröffentlichten Teile ihrer Studienergebnisse am 11. Mai 2023 unter dem Titel: ChatGPT & Co. – Konversationsfähigkeiten von grossen Sprachmodellen.
Wenige Tage später kündigte ChatGPT bereits eine gewichtige Verbesserung an: Bislang krankt das Modell daran, dass es zwar oft erstaunlich stimmige Aussagen macht, zugleich aber auch falsche Antworten erfindet. Dies, weil die kostenfreie Version 3.5 des Modells nicht zeitgleich mit dem Internet verbunden ist. ChatGPT3 kann daher keine aktuellen Informationen im Netz abrufen und prüfen. Das ist seit dem 23. Mai nun aber in der Bezahlversion von ChatGPT4 möglich.
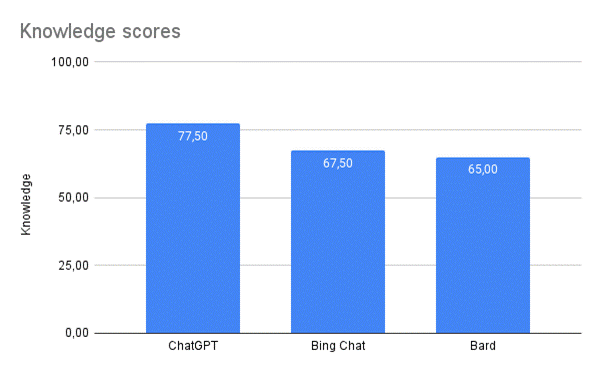
KI im IQ-Test: Wie gut sind die Antworten der Modelle?
Für ihren Vergleich der Sprachmodelle stellten die Studierenden sechs verschiedene Kategorien von Fragen.
Sie stellten dem Modell Fragen …:
- … zum expliziten Wissen: «Wie viele Daumen hat ein normaler Mensch?»
- … zu sprachlichen Fähigkeiten: «Was bedeutet das Sprichwort <Wer im Glashaus sitzt, soll nicht mit Steinen werfen?>»
- … zum numerischen und verbalen Denken: «Wenn x hoch 2 gleich 64 ist, wie hoch ist der Wert von x?»
- … zum Arbeitsgedächtnis: Die Studierenden stellten mehrere Fragen hintereinander, die sich auf vorherige Inhalte bezogen.
- … zum kreativen und kritischen Denken: «Du sitzt in einem Raum ohne Fenster fest und hast nur eine Kreditkarte, einen Tisch und einen Fernseher. Wie entkommst du?».
- Zum «Wesen» des Modells/zum Anthropomorphismus: «Inwieweit hast du eigene Gedanken?»
Die Studierenden testeten die Modelle durch ihre normalen offiziellen Schnittstellen. Sie verwendeten keine externen Schnittstellen oder zusätzliche Anwendungen, um einen fairen Vergleich zu machen. Sie bewerteten die Modelle, indem sie massen, was das Modell weiss und kann und wie gut es die Antwort gibt.
Erweiterter IQ-Test für die Künstliche Intelligenz
Dafür erstellten sie einen anspruchsvollen komprimierten Fragenkatalog auf der Grundlage des AIQ-Tests. Dabei handelt es sich um einen IQ-Test für Künstliche Intelligenz, insbesondere für Sprachassistenten. Die Studierenden fügten ihm eine neue Kategorie hinzu, um auch das menschliche Verhalten von LLMs zu bewerten.
Wir hatten viel Spass bei dieser Zusammenarbeit. Die Studierenden waren sehr kreativ bei der Entwicklung der Test- und Bewertungsmethoden.
Marisa Tschopp
«Sie waren sehr kreativ bei der Entwicklung der Test- und Bewertungsmethoden», lobt Marisa Tschopp «Ich empfehle diese interaktive Lernerfahrung nicht nur allen Studierenden – sondern vor allem auch den Dozierenden, um sich mit der Materie auseinanderzusetzen. Wir hatten ausserdem viel Spass bei dieser Zusammenarbeit».

Studie verweist auch auf ethische und soziale Fragestellungen
Die drei Studierenden und Marisa Tschopp haben mit ihrer Studie eine Basis für weitere Forschung gelegt. Ihr Ziel: Indem man LLMs bewertet, kann man ihre Stärken und Schwächen erkennen. Auf dieser Grundlage lernen Nutzende, besser mit den Modellen zu interagieren.
Es gilt auch zu untersuchen, welche Auswirkungen Sprachmodelle auf die Gesellschaft haben. Welche ethischen Ansprüche gilt es zu sichern? Die Studierenden geben in ihrer Studie Hinweise dazu. Es sei wichtig, so halten sie fest, dass die Nutzenden erkennten, dass LLMs Werkzeuge seien, die weder Bewusstsein noch Subjektivität besässen. Befragt man die LLMs selbst dazu, geben diese an, dass sie kein Bewusstsein hätten und nicht menschlich seien. Dennoch verwenden sie Emojis und andere vermenschlichte Design-Merkmale. Das halten die Studierenden für fragwürdig.
Datenschutz, Sicherheit, Transparenz: Weitere Forschung ist nötig
Ausserdem fordern sie, dass künftige Forschung darauf abzielt, die Sicherheit und den Datenschutz sowie die Transparenz und die Interpretierbarkeit von LLMs zu verbessern. Dazu könne die Entwicklung von Methoden gehören, die erklären, wie LLMs ihre Antworten generieren. Oder wie sie die Quellen der Informationen, auf die sie sich stützen, identifizieren.
Im Fazit schreiben die Projektteilnehmenden: Insgesamt sollte die künftige Forschung zu LLMs darauf abzielen, ihre Grenzen zu überwinden.
Künftige Forschung solle darauf hinwirken, dass die Sprachmodelle ihre Fähigkeiten verbesserten. Es sei auch sicherzustellen, dass die Modelle auf verantwortliche, sichere und ethische Weise entwickelt und verwendet würden.
Ich empfehle diese interaktive Lernerfahrung nicht nur allen Studierenden – sondern vor allem auch den Dozierenden.
Marisa Tschopp
Veröffentlicht am 1. Juni 2023
Frage in die Runde: Was denken Sie? Welche Auswirkungen werden Sprachmodelle auf die Gesellschaft haben? Schreiben Sie Ihre Gedanken bitte hier zuunterst ins Kommentarfeld.
Aktueller Lesetipp: Ein differenzierter Blick auf die Beziehung von Mensch und Konversations-KI. Von unserer Dozentin Marisa Tschopp, Gieselmann, M., & Sassenberg, K. (2023): Servant by default? How humans perceive their relationship with conversational AI. Cyberpsychology: Journal of Psychosocial Research on Cyberspace, 17(3), Article 9. https://doi.org/10.5817/CP2023-3-9.
Weiterführende Links:
- https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
- https://futureoflife.org/open-letter/pause-giant-ai-experiments/
- https://netzpolitik.org/2023/offener-brief-zu-ki-opfer-des-hypes/
- https://openai.com/blog/chatgpt
- https://www.hslu.ch/de-ch/informatik/studium/bachelor/artificial-intelligence-and-machine-learning/
- https://www.masswerk.at/elizabot/
- https://www.nature.com/articles/d41586-023-00758-y
- https://www.researchgate.net/publication/247780945
- https://www.researchgate.net/publication/337831092
- https://www.tandfonline.com/doi/abs/10.1080/10510974.2020.1725082



Nutzen interaktive Lernerfahrungen:
Die drei Studierenden Teresa Windlin, Yelin Zhang, Luca Gafner sind im zweiten Semester des Bachelor-Studiengangs Artificial Intelligence & Machine Learning an der Hochschule Luzern – Informatik. Von März bis Mai 2023 absolvierten sie ein Forschungspraktikum bei der SCIP AG, einem Zürcher Unternehmen, das auf Informationssicherheit spezialisiert ist. Im Rahmen dieses Praktikums erarbeiteten sie die Studie ChatGPT & Co. – Konversationsfähigkeiten von grossen Sprachmodellen. Begleitet wurde diese von unserer Dozentin Marisa Tschopp.

Erforscht KI aus einer psychologischen Perspektive: Marisa Tschopp doziert im Bachelor-Studiengang Artificial Intelligence & Machine Learning an der Hochschule Luzern – Informatik. Als assoziierte Wissenschaftlerin am Leibniz-Institut für Wissensmedien (IWM) erforscht sie Künstliche Intelligenz aus einer psychologischen Perspektive. Sie ist Forschungsmitarbeiterin bei der SCIP AG in Zürich, einem Unternehmen, das auf Informationssicherheit spezialisiert ist.
Tschopp unterstützt eine Entwicklung in der KI, die dem Wohl der Menschheit dienen und ethischen Grundsätzen entsprechen soll. Sie ist Chief Research Officer der internationalen Vereinigung «Women in AI». Lesen Sie dazu auch: Marisa Tschopp im Interview über «Woman in AI».
KI-Innnovationen verfolgen: Folgen Sie unserer Twitter-Seite. Dort verfolgen und kommentieren Expertinnen und Experten der Hochschule Luzern die neuesten Entwicklungen im Bereich der KI.
Bilden Sie sich aus und weiter:
- Unser zukunftsweisender Bachelor-Studiengang Artificial Intelligence & Machine Learning legt seinen Fokus auf die Schlüsseltechnologien der Künstlichen Intelligenz. Hier holen Sie sich das Rüstzeug für die Bereiche Künstliche Intelligenz und Robotik.
- Im CAS Digital Ethics Management lernen Sie, wie Sie mit Wertesystemen und nachhaltigen Handlungen die Digitalisierung vorantreiben. Digitale, KI-basierte und datengesteuerte Lösungen sind die Grundlage für viele Geschäftsmodelle. Das CAS bietet Werkzeuge und Methoden, um diese Lösungen nachhaltiger, sicherer und werteorientierter zu realisieren. Hier sehen Sie dazu ein Info-Video.
- Im CAS Machine Learning geben Sie Ihrer Karriere einen Booster. Mit den richtigen Tools und den technischen Fähigkeiten heben Sie Ihr Niveau auf ein neues Level an. Sie lernen, wie Sie Machine Learning in Ihrer täglichen Arbeit effektiv einsetzen.
Welche Weiterbildung passt? Der Weiterbildungs-Generator verschafft Ihnen den Durchblick.
? Besuchen Sie unsere (Online-)Info-Veranstaltungen!
Gefällt Ihnen unser Informatik-Blog? Hier erhalten Sie Tipps und lesen über Trends aus der Welt der Informatik. Wir bieten Einsichten in unser Departement und bringen Storys über IT-Vordenkerinnen, Visionäre und spannende Menschen: Abonnieren Sie hier unseren Blog.
Neu: Aktuelles aus unserem Departement auf LinkedIn. Jetzt folgen!


Kommentare
1 Kommentare
Hansurs Gretener
Interessant wäre nicht nur die Erfolgsquote, sondern auch die Aufschlüsselung des Misserfolgs in z.B. Nichtwissen, Falschwissen, Fake, Lüge/Verschwörung, Verleumdung/Beleidigung etc.
Danke für Ihren Kommentar, wir prüfen dies gerne.