12. August 2024
Revolution in der Portfoliooptimierung? Wie Künstliche Intelligenz die Anlagewelt verändern könnte
Traditionelle Ansätze der Portfoliooptimierung basieren auf Schätzungen der Renditeverteilungen und Kovarianzmatrizen, sind jedoch oft fehleranfällig. Ein vom IFZ in Zusammenarbeit mit der OLZ durchgeführtes Forschungsprojekt nutzt maschinelles Lernen, um diesen ersten Schritt zu umgehen und direkt aus den Daten optimale Portfoliogewichte zu lernen. Durch den Einsatz von Deep Reinforcement Learning erzielt das Modell beeindruckende Ergebnisse. In der untersuchten Periode von November 2017 bis August 2023 erzielte das neue Modell eine beeindruckende Gesamtrendite (nach Kosten) von 148.7%, während ein gleichgewichtetes Portfolio der fünf Anlageklassen nur 31.0% erzielte. Ist das der Start einer Revolution? Im heutigen Blog zeigen wir die ersten Erkenntnisse auf und zeigen, in welchen Bereichen wir noch Verbesserungspotenzial sehen.
Das IFZ hat sich im vergangenen Jahr gemeinsam mit der OLZ AG erfolgreich für ein Innosuisse Innovationsprojekt beworben, um an Finanzmarkt-Anwendungen des Reinforcement Learning, einem Teilgebiet der künstlichen Intelligenz, zu forschen.
Das Ziel dieses Projekts ist es, zu evaluieren wie die Asset Allokation von Pensionskassen in Bezug auf Wertentwicklung und gleichzeitige Absicherung des Deckungsgrads mittels Reinforcement Learning optimiert werden kann. Diese Klasse der Algorithmen bildet ein recht neues Teilgebiet der künstlichen Intelligenz und findet bereits in zahlreichen Branchen Anwendung.
«Technischer» Hintergrund des Projekts
Üblicherweise werden systematische Anlageentscheidungen in der Asset Allokation und in der Portfoliooptimierung in zwei Schritten getroffen: Zuerst wird die gemeinsame Verteilung der zukünftigen Renditen der Anlageinstrumente geschätzt. Im einfachsten Fall, zurückgehend auf Harry Markowitz (1952), ist dies eine multivariate Normalverteilung, die durch den Erwartungswert und die Kovarianzmatrix bereits vollständig bestimmt ist. Aufgrund dieser geschätzten Verteilung werden in einem zweiten Schritt die optimalen Portfoliogewichte bestimmt. Optimalität bezieht sich hierbei oft auf das sog. Mean-Variance Kriterium, welches auf einen Trade-Off zwischen erwarteter Rendite und tolerierbarem Risiko hinausläuft. Es sind jedoch auch andere Kriterien möglich, z.B. die Minimierung der Schwankungsbreite des Portfolios (Minimum-Variance) oder das Ausbalancieren der Risikobeiträge der einzelnen Anlageinstrumente (Risk Parity).
Der oben beschriebene erste Schritt dieser Vorgehensweise ist in der Praxis mit einigen Problemen behaftet. Insbesondere erfordert er eine Reihe von Annahmen, etwa bezüglich der Verteilungsfamilie der Renditen oder der zeitlichen Entwicklung der Volatilität. Jede Annahme birgt aber das Risiko, dass sie in der Praxis nicht erfüllt ist. Selbst bei Korrektheit der Annahmen kann die Schätzung der Verteilung, konkret etwa der Kovarianzmatrix, problematisch sein, insbesondere wenn das Anlageuniversum gross ist und nur eine begrenze Menge an Daten zu Verfügung stehen. Üblicherweise werden diese Schwachstellen des Mean-Variance Ansatzes durch eine Vielzahl verschiedener Hilfsmittel wie Shrinkage-Schätzer, Regularisierung und ein gut durchdachtes Design der Nebenbedingungen adressiert.
Der neuartige Ansatz dieses Forschungsprojektes ist es hingegen, diesen ersten Schritt der Schätzung der Verteilung vollständig zu umgehen, und die optimalen Portfoliogewichte stattdessen direkt aus den Daten zu lernen. Dies wird möglich durch den Einsatz von maschinellem Lernen, der Basis moderner künstlicher Intelligenz. Wir bedienen uns des sogenannten Deep Reinforcement Learnings – einer revolutionären Technik, die es KI-Modellen ermöglicht, in anspruchsvollen Spielen wie Go oder Schach übermenschliche Leistungen zu erbringen und vielen Bereichen Anwendungen findet, so z.B. bei der Entwicklung von selbstfahrenden Auto, von Robotern, oder auch bei der Diagnose und Behandlung von Krankheiten. Diese Technologie befähigt unsere Modelle, sich in dynamischen Umgebungen wie dem Finanzmarkt eigenständig zurechtzufinden und kontinuierlich aus ihren Fehlern zu lernen.
Im ersten Teil unseres Forschungsprojekts konzentrieren wir uns auf die optimale Allokation zwischen verschiedenen Anlageklassen mithilfe von liquiden ETFs: Aktien (Vanguard Total Stock Market ETF), Immobilien (Vanguard Real Estate Index ETF), Anleihen (iShares Core U.S. Aggregate Bond ETF), Rohstoffe (Invesco DB Commodity Index ETF), sowie Gold (Spotpreis). Mittels dieser Instrumente wird der Grossteil des Anlageuniversums eines typischen institutionellen Investors repräsentiert. Anlagen in Private Equity oder sonstigen alternativen Anlagen sind nicht berücksichtigt, da hierzu keine ausreichenden Datenreihen verfügbar sind.
Erste Ergebnisse: Gesamtrendite von 148.7% statt 31%
Die Ergebnisse unseres neuartigen K.I. Ansatzes sind sehr vielversprechend: In der untersuchten Periode von November 2017 bis August 2023 erzielte unser Modell (OLZ Reinforcement Learning Allokation) eine beeindruckende Gesamtrendite (nach Kosten) von 148.7%, während ein gleichgewichtetes Portfolio der fünf Anlageklassen nur 31.0% erzielte. Ein typisches Pensionskassen-Portfolio (30% Aktien, 30% festverzinsliche Wertpapiere, 30% Immobilien und 10% Rohstoffe) erzielte sogar nur eine kumulierte Rendite von 20.6%. Die Wertentwicklung unserer Strategie, dargestellt in Abbildung 1, übertrifft somit deutlich die beiden Benchmarks.
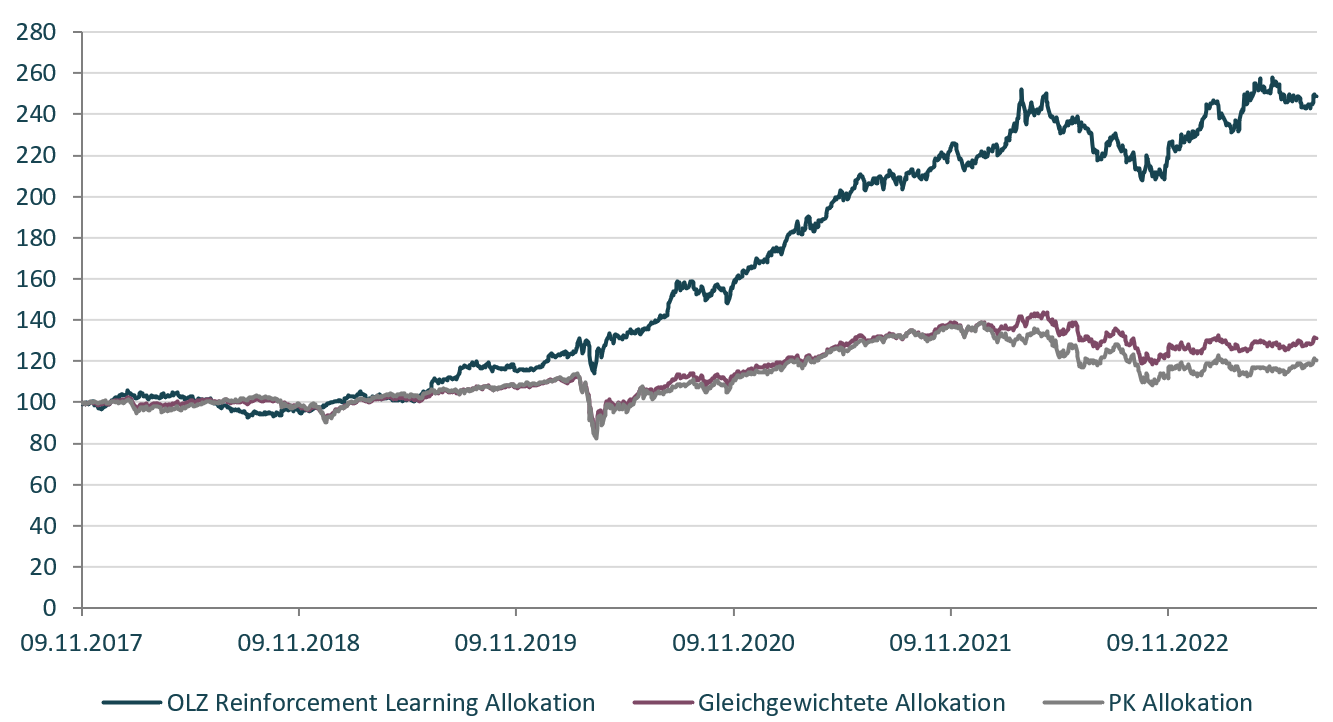
Abbildung 1: Wertentwicklung der OLZ Reinforcement Learning Allokation und Vergleich zur gleichgewichteten Allokation und einer typischen PK Allokation.
Da die Volatilität aller drei Portfolios recht ähnlich ist (12.3% im Vergleich zu 11.5% bzw. 13.8%), ergibt sich für die künstliche Intelligenz ein hervorragendes Sharpe Ratio von 1.37, welches signifikant höher ist als das der Vergleichsindizes (0.41 bzw. 0.24). Betrachtet man den Maximum Drawdown, also den grösstmöglichen Verlust im Anlagezeitraum, so erzielte unser Modell mit -17.5% ein deutlich besseres Worst-case Szenario als die Vergleichsportfolios (Gleichgewichtetes Portfolio -22.9%, PK-Portfolio -27.6%). Auch im Vergleich zur vermeintlich sichersten Anlageklasse der festverzinslichen Wertpapiere (-21.7%) wurde ein besserer Kapitalerhalt erzielt. Interessanterweise bevorzugt die künstliche Intelligenz über weite Teile der Analyseperiode eine überdurchschnittlich hohe Allokation in Gold, insbesondere während der Corona-Pandemie.
Weiteres Vorgehen
Trotz dieser vielversprechenden Ergebnisse stehen wir noch vor einigen Herausforderungen, bevor aus dieser hochinnovativen Strategie ein marktfähiges Anlageprodukt entwickelt werden kann. Gemeinsam mit unserem Praxispartner arbeiten wir daran, die Robustheit unseres Modells weiter zu verbessern und es widerstandsfähiger gegenüber Veränderungen der Datengrundlage zu machen. Zudem arbeiten wir weiterhin daran, Allokationen mit höherer praktischer Relevanz zu generieren, z.B. indem den einzelnen Anlageklassen realistische Bandbreiten zugewiesen werden. Hiermit wollen wir sicherstellen, dass unsere von künstlicher Intelligenz entwickelten Lösungen alle Anlagerestriktionen einer Pensionskasse vollständig erfüllen.
Im weiteren Verlauf des Projekts sollen zudem Portfolios auf Einzelaktien optimiert werden, sodass die künstliche Intelligenz fortwährend aus einer Vielzahl von Marktinformationen lernt ein optimales Portfolio zu konstruieren. Über diese und weitere Entwicklungen werden wir Sie in den nächsten Monaten auf dem Laufenden halten.
Kommentare
18 Kommentare
Ruedi Büchi
23. August 2024
Sehr spannender Artikel und beeindruckende Ergebnisse! Ich habe zwei Fragen: Wie wurde die abhängige Variabel definiert? Die Portfolio-Allokation welche im Betrachtungsmonat die beste risikoadjustierte Rendite geliefert hätte? Und welche Inputvariablen wurden zum trainieren des Modelles verwendet?
Sacha Widin
18. August 2024
Interessanter Ansatz. Backtest sieht (wie fast immer) gut aus. Aber es stellen sich einige Fragen zur obigen Graphik und den Daten: die Instrumente sind a) vermutlich in USD (d.h. nicht abgesichert gegen CHF) gerechnet, was in diesem Fall eher "schlecht" für dieses Modell war, sofern die Performance in CHF ausgewiesen ist? Interessant wäre es zu sehen nach Absicherung vs. CHF, welche über die Zeit 3-4% p.a. kostete), b) das Modell ist sehr stark US-Kapitalmarkt bezogen (US Aktien haben z.B. CH Aktien massiv outperformed in dieser Periode), c) wie gross war der active share gegen den 30/30/30/10 Benchmark? Die BVG Richtlinien sind vermutlich mit diesem Modell nicht eingehalten worden (z.B. in der maximalen Fremdwährung und max. Aktienquote, sowie anderen Bandbreiten)? Wenn ja ist dieser Vergleich mit der "PK Allokation" oben in der Graphik nicht sinnvoll und zu hinterfragen, eine Schweizer PK investiert primär in CH Aktien, -Anleihen, -Immobilien und Schweizer Franken. Oder habe ich etwas übersehen?
Simon Broda
18. August 2024
In der Tat ist das Modell derzeit US-zentrisch; auch die Performance in der Grafik ist in USD ausgewiesen. Wie so häufig ist dies durch Datenverfügbarkeit getrieben. Auch vor dem Hintergrund der BVG-Richtlinien wäre die Allokation in derzeitiger Form also für eine Schweizer PK tatsächlich nicht ohne weiteres anwendbar. Das Modell in seiner derzeitigen Form ist eher als Proof of Concept zu betrachten. Das Forschungsprojekt steht im Moment etwa an der Halbzeit, und genau diese Fragen werden im weiteren Verlauf des Projektes zu klären sein.
Martin Gfeller
16. August 2024
Ist geplant, in einem Paper die Methodik genauer zu beschreiben? Die Reaktionen auf meinen LinkedIn-Post (https://www.linkedin.com/feed/update/urn:li:activity:7228784104920477696/) sind skeptisch bezüglich eines Overfits, resp. Anpassung des Modells an die gewählte Periode. Eine Analyse (falls möglich peer-reviewed) könnte dies entkräften.
Simon Broda
16. August 2024
Ja, eine Publikation hierzu ist geplant.
Daniel Strub
13. August 2024
Interessant, und trotzdem höchste Vorsicht geboten. Es ist verpönt, Entwicklung und Testing mit den selben Daten vorzunehmen. Wir haben es hier nicht mit physikalischen Rahmenbedingungen zu tun. Ich habe noch nie erlebt, dass die auf der Basis historischer Daten entwickelte und für den gleichen Zeitintervall getestete Strategien dann die geschürten Erwartungen erfüllen konnte. Als Dino der Branche würde ich die Sache als neuen naiven Versuch bezeichnen, den heiligen Gral zu finden.
Simon Broda
13. August 2024
Die gezeigte Performance von November 2017 bis August 2023 ist selbstverständlich out of sample. Trainiert wurde das Modell mit Daten vom März 2006 bis November 2017.
Simon Broda
13. August 2024
Trotzdem ist past performance natürlich keine Garantie für die Zukunft. Vorsicht ist immer geboten.
Ralph Kleeb
13. August 2024
In der Rückwärtsbetrachtung wären stets hervorragende Rendite möglich gewesen. Das war schon vor jahrzehnten mit klassischen Regressionsmodellen der Fall. Nur die Aussagekraft für die Zukunft blieb dann stets bescheiden. Das gilt übrigens auch für meinen 3a-Fonds von OLZ. Zu denken geben muss jedoch der Vergleich v.a. mit dem PK-Benchmark. Höhere Vola, höherer Maxdrawdown und magerste Rendite. Von den hohen Anlagekosten in diesem Bereich ganz zu schweigen. Im PK-Anlagebereich läuft etwas ziemlich schief. Gibt es dazu auch aktuelle Forschungsergebnisse?
Martin Gfeller
12. August 2024
Erleben wir hier die Obsoleszenz der klassischen statistischen Methoden im Asset Management? Oder sind die klassischen Ansätze als Leitplanken (guard rails) noch nützlich? Gibt es ein längeres Backtesting, auch das auch grosse Verwerfungen umfasst?
Simon Broda
12. August 2024
Von Obsoleszenz würde ich nicht sprechen. Aber sicher werden neue Methoden Einzug finden, so wie in jedem anderen Bereich unseres Lebens auch.
Simon Broda
12. August 2024
PS: Ein längeres Backtesting ist mit diesem Datensatz leider nicht möglich, zumindest nicht ohne den train/test split zu ändern. Wir sind hier eingeschränkt durch den DBC ETF, der erst 2006 aufgelegt wurde. Wie ich andernorts schrieb, trainieren wir das Modell mit Daten vom März 2006 bis November 2017, und testen es wie gezeigt in der Periode November 2017 bis August 2023 out of sample. Allerdings experimentieren wir im Moment mit einem anderen Datensatz. Die Idee ist, zum Training nicht ETFs zu verwenden, sondern direkt die zugrundeliegenden Indices (konkret Russel 3000, GSCI, DJUSRE und WGBI). Diese Daten stehen ab 1993 zur Verfügung. Die Indices sind natürlich nicht handelbar, aber unsere Hoffnung ist, dass das Modell dennoch relevantes aus ihnen lernen kann.
Dominic Frehner
12. August 2024
Vielen Dank für den interessanten Beitrag. Es spielt immer eine Rolle, mit welcher Strategie man das Portfolio optimieren möchte. Sie haben insbesondere Trend Following Assets ausgewählt, wobei bei einem Trend grosse Profite realisiert werden können. Dies erkennt man gut, da der Markt weltweit nach Corona stark zugelegt hat. die Frage ist, ob man wirklich knapp 2.5 Jahre den Algorithmus hätte laufen lassen, ohne wirklich Gewinn zu erzielen. Da hat man bestimmt noch Optimierungsbedarf in einem bärischen Markt. Ich gehe davon aus, dass man eine "Buy and Hold"-Strategie in diesem Fall gewählt hat. Was mich sehr interessieren würde, ist die In-Sample und Out-of-Sample Verteilung. Wie viele Jahr bis 2023 waren Out-of-Sample gebacktestet worden? Ich verwende selbst ML/AI bei Risk Management, Portfolio Optimization und bei Trading Strategien. Es ist jedoch wichtig, dass das Modell nicht zu "overfitted" wird und man eben mit In-Sample und Out-of-Sample Daten arbeitet. Zudem sind 6 Jahre viel zu wenig Daten. Ich lasse die Algorithmen immer mit mindestens 10 Jahren Vergangenheitsdaten rechnen. Davon sind 7 Jahre In-Sample und 3 Jahre Out-of-Sample.
Simon Broda
12. August 2024
Die gezeigte Performance von November 2017 bis August 2023 ist out of sample. Trainiert wurde das Modell mit Daten vom März 2006 bis November 2017, der train-test split ist also 2/3 - 1/3. Die Strategie ist nicht buy and hold, sondern monthly rebalancing.
Simon
12. August 2024
Wurde das Modell auch mit out-of sample Daten getestet?
Simon Broda
12. August 2024
Die gezeigte Performance von November 2017 bis August 2023 ist selbstverständlich out of sample. Trainiert wurde das Modell mit Daten vom März 2006 bis November 2017.
Walter Grimm
12. August 2024
Gute Sache, weiter damit - kann was Gutes werden um die so/zu vielen Pseudo-aktiven Portfolio-Manager zu bereinigen... ebenso die viel zu teuren "pseudoaktiven Funds". Wieso ist die Performance erst ab 2020 markant verbessert?
Simon Broda
12. August 2024
Das untersuchen wir noch. Aus den Daten sehen wir, dass das Modell nach dem CoViD-Crash seine Allokation in Aktien und Rohstoffe (ausser Gold) erhöht hat, zulasten vorrangig von Gold. Hierdurch hat es verhältnismässig stark vom Rebound profitiert.
Danke für Ihren Kommentar, wir prüfen dies gerne.